Jupyter Notebook Test
Blogapi| 27 Mar 2018import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
import pickle as pkl
from scipy.stats import ttest_ind
from sklearn.preprocessing import RobustScaler
from sklearn.manifold import TSNE
from sklearn.mixture import GaussianMixture
font= matplotlib.font_manager.FontProperties(fname= 'C:\Windows\\Fonts\\조선일보명조.ttf').get_name()
matplotlib.rc('font', family=font)
데이터를 로드하고 분석에 적합한 형태로 변환함
df_bymonth= pd.read_csv('./Pre_processed_data/groupby_ID_YEARMONTH.csv')
pt_bytsne= pd.read_pickle('./pkl_result/data_tSNE_dim2_perplex30.pkl')
df_raw= pd.read_csv('./Pre_processed_data/merged_dataframe_shopping.csv', delimiter= ',', encoding= 'euc-kr')
df_grouped= df_raw.sort_values('ID')
agg_func= {'RCT_NO': 'count', 'BIZ_UNIT': lambda x: x.nunique(), 'PD_S_C': lambda x: x.nunique(), \
'BR_C': lambda x: x.nunique(), 'BUY_AM': 'sum'}
df_grouped= df_grouped.groupby('ID').agg(agg_func).reset_index(drop= False)
df_demo= df_raw[['ID', 'AGE_PRD', 'IS_MALE', 'IS_FEMALE', 'PRVIN']].drop_duplicates(subset= 'ID').sort_values('ID').reset_index(drop= True)
df_byitem= pd.read_pickle('./pkl_result/item_selected_by_middleline.pkl')
df_byitem= df_byitem.reset_index(drop=False)
df_item_consumed= pd.read_pickle('./pkl_result/item_selected_by_middleline.pkl')
df_item_consumed.reset_index(drop= False, inplace= True)
def plot_results(X, Y_= None):
try:
if Y_.any():
for i in range(Y_.nunique()):
grp= sns.regplot(x= X.loc[Y_==i, 0], y= X.loc[Y_==i, 1], fit_reg= False, scatter_kws= {'s': 2})
plt.show()
except AttributeError:
grp= sns.regplot(x= X.iloc[:,0], y= X.iloc[:, 1], fit_reg= False, scatter_kws= {'s': 2})
plt.show()
def plot_clusters(X, Y_):
for i in sorted(Y_.unique().tolist()):
grp= sns.regplot(x= X.iloc[:,0], y= X.iloc[:, 1], fit_reg= False, scatter_kws= {'s': 2})
grp= sns.regplot(x= X.loc[Y_==i, 0], y= X.loc[Y_==i, 1], fit_reg= False, scatter_kws= {"color": "red", 's': 2})
plt.show()
prefered_item_dict_05= {}
ft_dict= {}
def find_prefered_item(df, label, p_val= 0.05):
for i in sorted(label.unique().tolist()):
ft_dict[i]= df.loc[label==i, :]
print('\nfor cluster {}:\n'.format(str(i)))
prefered_item_dict_05[i]= []
for item in df.columns.values.tolist():
(stat_item, p_val_item)= ttest_ind(ft_dict[i][item], df[item], equal_var= False)
if p_val_item< p_val and stat_item>0:
print('item {} has different mean with total dataset; ({}, {})'.format(item, stat_item, p_val_item))
prefered_item_dict_05[i].append(item)
def find_prefered_by_clusters(df, label, i, j, p_val= 0.05):
for item in df.columns.values.tolist():
(stat_item, p_val_item)= ttest_ind(df.loc[label==i, item], df.loc[label==j, item], equal_var= False)
if p_val_item< p_val:
print('item {} has different mean with total dataset; ({}, {})'.format(item, stat_item, p_val_item))
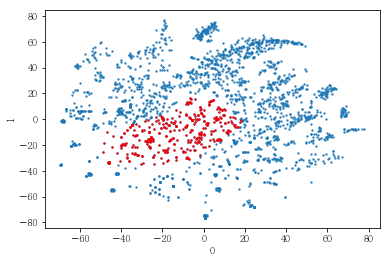
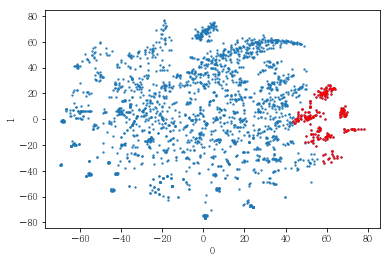
plot_results(pt_bytsne[[0,1]], pt_bytsne['y_14_clst'])
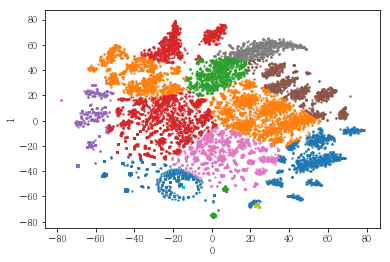
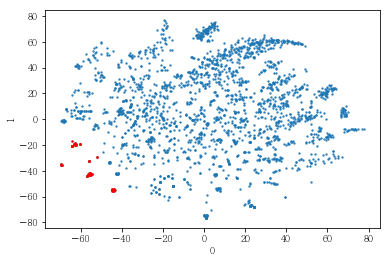
plot_clusters(pt_bytsne[[0,1]], pt_bytsne['y_14_clst'])
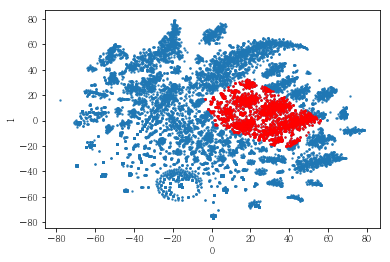
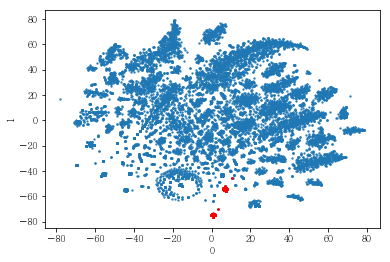
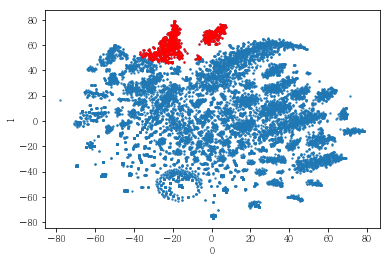
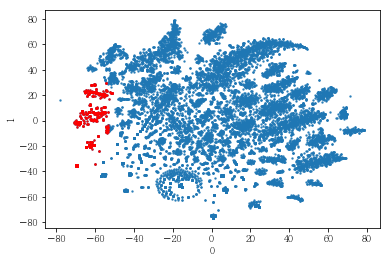
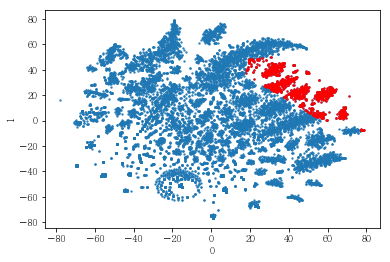
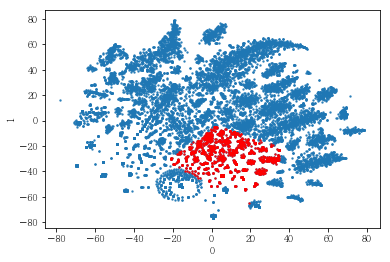
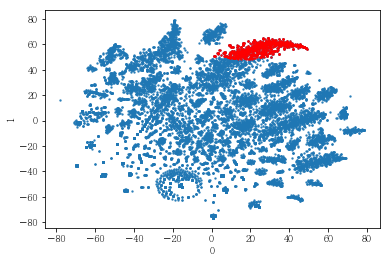
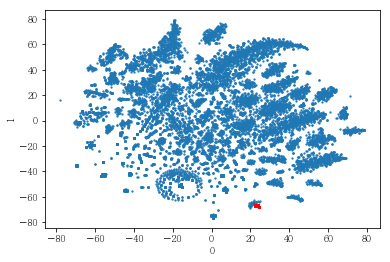

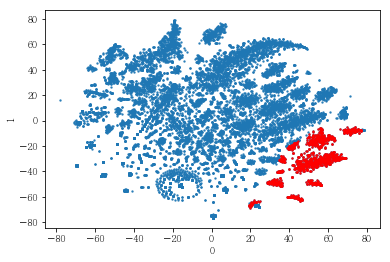
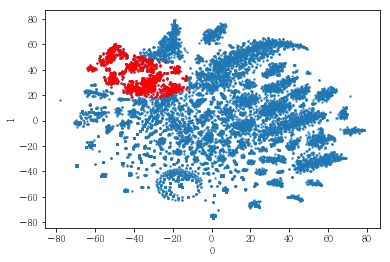
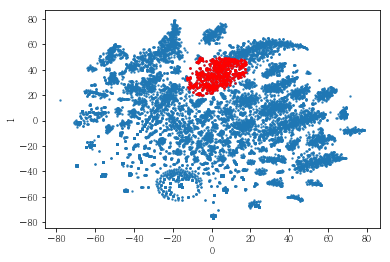
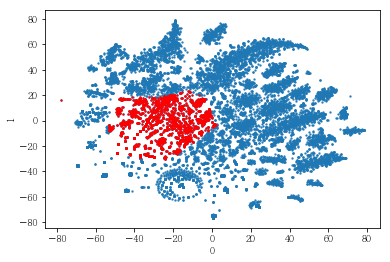
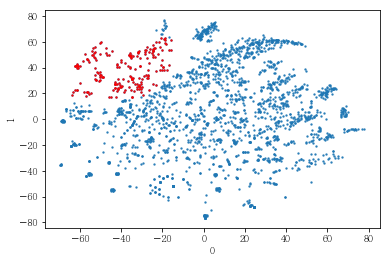
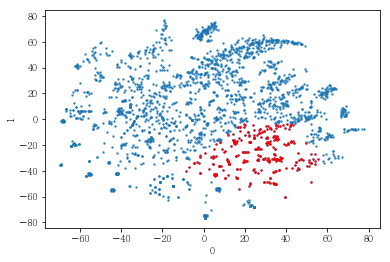
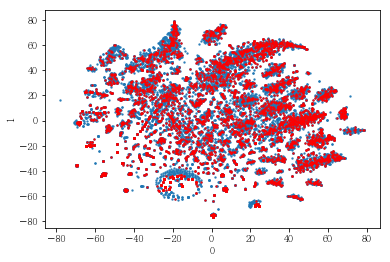
plot_clusters(pt_bytsne[[0,1]], df_demo['IS_FEMALE'])
#성별이 클러스터와 연관이 있는 인구통계 정보인지 확인함. 아래의 시각화 결과에 따르면, 성별은 클러스터를 구분짓는 요소는 아니지만 클러스터 내에서 소비 품목의 차이는 드러났음.
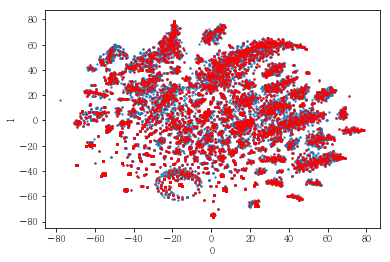
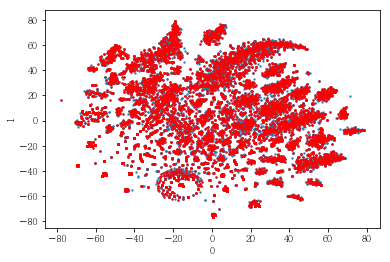
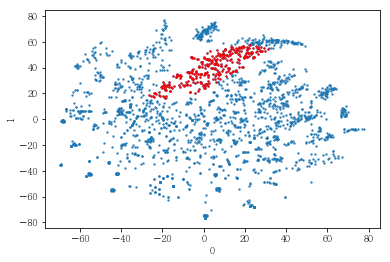
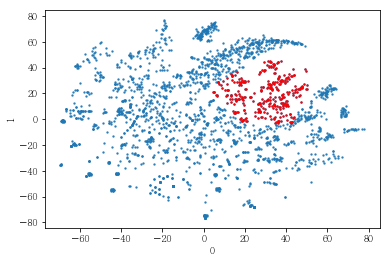
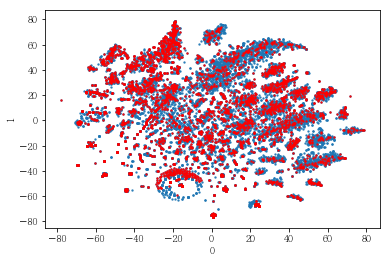
plot_clusters(pt_bytsne[[0,1]], df_demo['AGE_PRD'])
# 연령대의 경우도 마찬가지로 연령대와 관계 없이 폭넓게 분포하고 있었음.
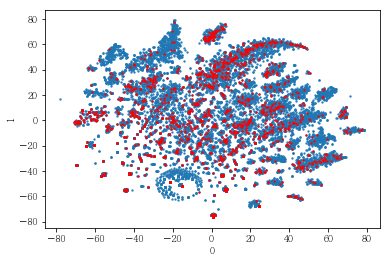
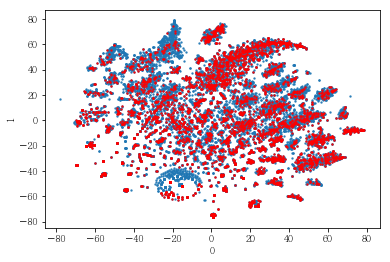
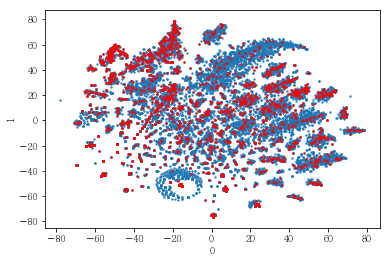
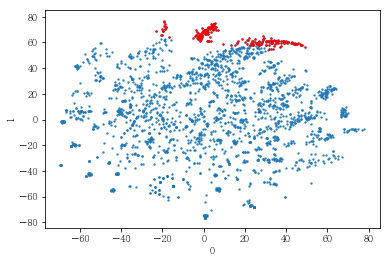
성별, 연령대 또는 나이에 따라 사용자를 나누어 클러스터링해 보았음. 아래는 여성 사용자만을 대상으로 클러스터링한 결과임
pt_bytsne= pd.concat([df_demo['ID'], pt_bytsne], axis= 1)
pt_female= pt_bytsne.loc[df_demo['IS_FEMALE']==1, :].reset_index(drop= True)
pt_female.head()
| ID | 0 | 1 | y_14_clst | y_28_clst | y_24_clst | |
|---|---|---|---|---|---|---|
| 0 | 2 | 53.016911 | -32.975819 | 10 | 8 | 8 |
| 1 | 3 | -22.183092 | 52.640892 | 3 | 9 | 9 |
| 2 | 6 | 42.187847 | 32.573856 | 5 | 17 | 17 |
| 3 | 7 | -27.630230 | 52.580269 | 3 | 12 | 12 |
| 4 | 8 | -5.850988 | 27.713455 | 12 | 3 | 3 |
pt_male= pt_bytsne.loc[df_demo['IS_FEMALE']==0, :].reset_index(drop= True)
gmm = GaussianMixture(n_components=14, covariance_type='full', random_state= 42).fit(pt_female[[0,1]])
label_dict[(2,i)]= pd.Series(gmm.predict(pt_female[[0,1]]))
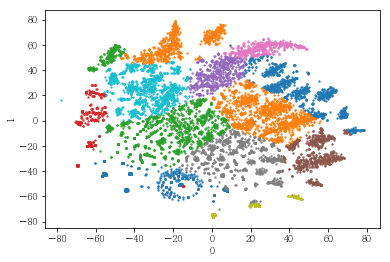
plot_results(pt_female[[0,1]], label_dict[(2,14)])
# 여성들만을 군집화한 경우에도 유사한 클러스터가 형성되는 것을 확인함
df_female= df_item_consumed.loc[df_demo['IS_FEMALE']==1, :].drop('ID', axis= 1).reset_index(drop= True)
df_female.head()
| H&B선물세트 | VIDEOGAME | 가공식품 | 가공우유 | 가구 | 가방브랜드 | 계절완구 | 고급 | 고양이용품 | 골프 | ... | 필기용품 | 한방차 | 한우선물세트 | 해초 | 헬스용품 | 호주산소고기 | 홍인삼 | 화과자 | 황태 | 훼이셜케어 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 6.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 4.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 14.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 18.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 23.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 149 columns
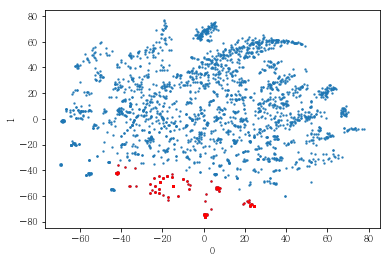
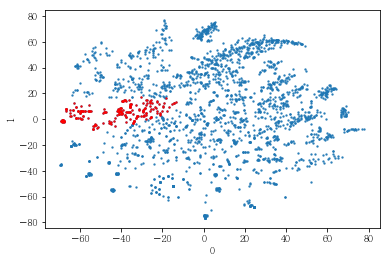
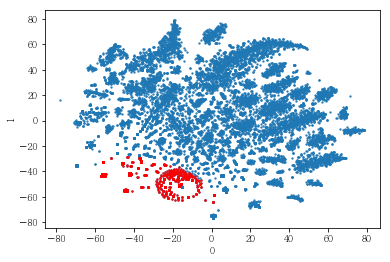
남성 사용자를 클러스터링해 보았음. 이 때 6번 클러스터와 7번 클러스터 간의 차이를 파악하였음.
pt_male= pt_bytsne.loc[df_demo['IS_FEMALE']==0, :].reset_index(drop= True)
df_male= df_item_consumed.loc[df_demo['IS_FEMALE']==0, :].drop('ID', axis= 1).reset_index(drop= True)
id_male= df_raw.loc[df_raw['IS_MALE']==1, 'ID'].drop_duplicates().sort_values().reset_index(drop= True)
df_demo_male= df_demo.loc[df_demo['ID'].isin(id_male), :].reset_index(drop= True)
df_male.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7003 entries, 0 to 7002
Columns: 149 entries, H&B선물세트 to 훼이셜케어
dtypes: float64(149)
memory usage: 8.0 MB
gmm = GaussianMixture(n_components=14, covariance_type='full', random_state= 42).fit(pt_male[[0,1]])
label_dict[(2, 14)]= pd.Series(gmm.predict(pt_male[[0,1]]))
plot_results(pt_male[[0,1]], label_dict[(2,14)])
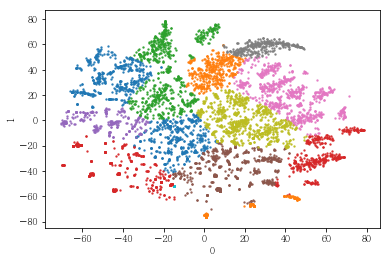
df_byitem.loc[df_demo['IS_MALE']==1].reset_index().loc[label_dict[(2,14)]==6, :].head()
| index | ID | H&B선물세트 | VIDEOGAME | 가공식품 | 가공우유 | 가구 | 가방브랜드 | 계절완구 | 고급 | ... | 필기용품 | 한방차 | 한우선물세트 | 해초 | 헬스용품 | 호주산소고기 | 홍인삼 | 화과자 | 황태 | 훼이셜케어 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 4 | 0.0 | 0.0 | 38.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 12 | 26 | 29 | 0.0 | 0.0 | 11.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 9.0 | 0.0 | 0.0 | 4.0 | 1.0 |
| 19 | 39 | 42 | 0.0 | 0.0 | 22.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 3.0 | 0.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| 22 | 46 | 50 | 0.0 | 0.0 | 9.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 15.0 | 14.0 | 0.0 | 0.0 | 0.0 |
| 26 | 52 | 56 | 0.0 | 0.0 | 13.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 151 columns
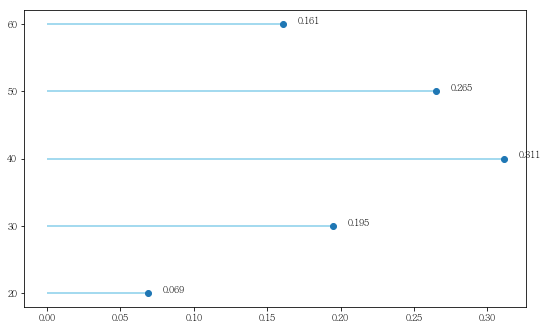
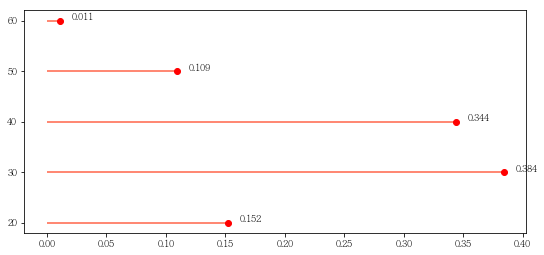
6번 클러스터와 7번 클러스터 간의 지표 차이를 파악하였음.
df_clst6= df_demo_male.loc[label_dict[(2,14)]==6, :]
df_clst7= df_demo_male.loc[label_dict[(2,14)]==7, :]
df_info6= df_grouped.loc[df_grouped['ID'].isin(df_clst6['ID']), :]
df_info7= df_grouped.loc[df_grouped['ID'].isin(df_clst7['ID']), :]
df_info6.head()
| ID | RCT_NO | BIZ_UNIT | PD_S_C | BR_C | BUY_AM | |
|---|---|---|---|---|---|---|
| 3 | 4 | 308 | 3 | 136 | 7 | 7970116 |
| 26 | 29 | 408 | 2 | 159 | 5 | 3756730 |
| 39 | 42 | 492 | 2 | 138 | 3 | 5425186 |
| 46 | 50 | 566 | 3 | 238 | 11 | 10626666 |
| 52 | 56 | 107 | 3 | 58 | 6 | 2197496 |
df_clst6.AGE_PRD.value_counts().sort_index()
20 55
30 156
40 249
50 212
60 129
Name: AGE_PRD, dtype: int64
df_value6= df_clst6.PRVIN.value_counts().sort_values()
df_value7= df_clst7.PRVIN.value_counts().sort_values()
df_ratio6= (df_value6/df_clst6.PRVIN.count()).apply(lambda x: round(x, 3))
df_ratio7= (df_value7/df_clst7.PRVIN.count()).apply(lambda x: round(x, 3))
num_of_range= range(1, df_value6.count()+1)
grp= plt.figure(figsize= (9,12))
ax= grp.add_subplot(211)
plt.hlines(y=num_of_range, xmin=0, xmax=df_ratio6, color='skyblue')
for i in num_of_range:
ax.annotate(df_ratio6.values.tolist()[i-1], xy=(df_ratio6.values.tolist()[i-1]+0.01, i+0.01), textcoords='data')
plt.plot(df_ratio6, num_of_range, "o")
plt.yticks(num_of_range, df_value6.index)
num_of_range= range(1, df_value7.count()+1)
grp= plt.figure(figsize= (9,9))
ax= grp.add_subplot(212)
plt.hlines(y=num_of_range, xmin=0, xmax=df_ratio7, color='tomato')
for i in num_of_range:
ax.annotate(df_ratio7.values.tolist()[i-1], xy=(df_ratio7.values.tolist()[i-1]+0.01, i+0.01), textcoords='data')
plt.plot(df_ratio7, num_of_range, "o", color= 'red')
plt.yticks(num_of_range, df_value6.index)
plt.show()
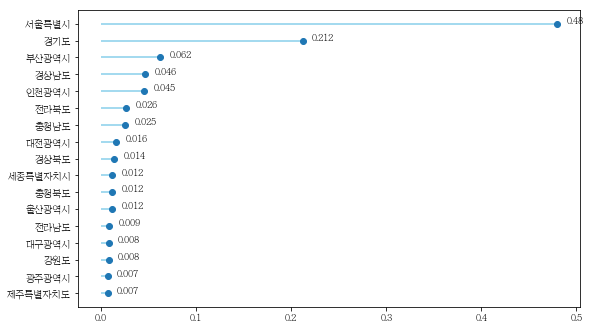

df_value6= df_clst6.AGE_PRD.value_counts().sort_index()
df_value7= df_clst7.AGE_PRD.value_counts().sort_index()
df_ratio6= (df_value6/df_clst6.AGE_PRD.count()).apply(lambda x: round(x, 3))
df_ratio7= (df_value7/df_clst7.AGE_PRD.count()).apply(lambda x: round(x, 3))
num_of_range= range(1, df_value6.count()+1)
grp= plt.figure(figsize= (9,12))
ax= grp.add_subplot(211)
plt.hlines(y=num_of_range, xmin=0, xmax=df_ratio6, color='skyblue')
for i in num_of_range:
ax.annotate(df_ratio6.values.tolist()[i-1], xy=(df_ratio6.values.tolist()[i-1]+0.01, i+0.01), textcoords='data')
plt.plot(df_ratio6, num_of_range, "o")
plt.yticks(num_of_range, df_value6.index)
num_of_range= range(1, df_value7.count()+1)
grp= plt.figure(figsize= (9,9))
ax= grp.add_subplot(212)
plt.hlines(y=num_of_range, xmin=0, xmax=df_ratio7, color='tomato')
for i in num_of_range:
ax.annotate(df_ratio7.values.tolist()[i-1], xy=(df_ratio7.values.tolist()[i-1]+0.01, i+0.01), textcoords='data')
plt.plot(df_ratio7, num_of_range, "o", color= 'red')
plt.yticks(num_of_range, df_value6.index)
plt.show()
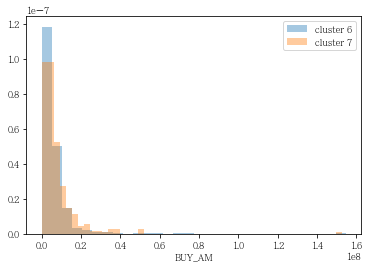
grp= sns.distplot(df_info6['BUY_AM'], label= 'cluster 6', bins= 30, kde= False, norm_hist= True)
grp= sns.distplot(df_info7['BUY_AM'], label= 'cluster 7', kde= False, norm_hist= True)
plt.legend()
plt.show()
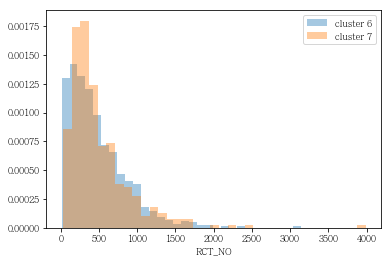
grp= sns.distplot(df_info6['RCT_NO'], label= 'cluster 6', bins= 30, kde= False, norm_hist= True)
grp= sns.distplot(df_info7['RCT_NO'], label= 'cluster 7', kde= False, norm_hist= True)
plt.legend()
plt.show()
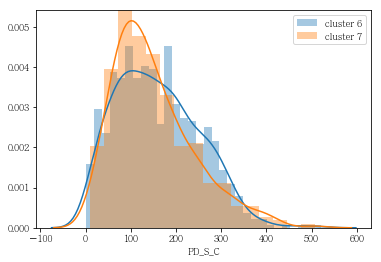
grp= sns.distplot(df_info6['PD_S_C'], label= 'cluster 6', bins= 30, kde= True)
grp= sns.distplot(df_info7['PD_S_C'], label= 'cluster 7', kde= True)
plt.legend()
plt.show()
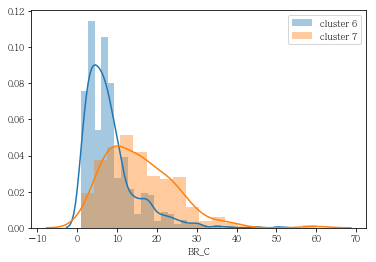
grp= sns.distplot(df_info6['BR_C'], label= 'cluster 6', bins= 30, kde= True)
grp= sns.distplot(df_info7['BR_C'], label= 'cluster 7', kde= True)
plt.legend()
plt.show()
20-40대 서울 거주 여성을 클러스터링함
pt_specified= pt_bytsne.loc[(df_demo['IS_FEMALE']==1)&((df_demo['AGE_PRD']==20)|(df_demo['AGE_PRD']==30)|(df_demo['AGE_PRD']==40))&(df_demo['PRVIN']=='서울특별시'), :].reset_index(drop= True)
df_specified= df_item_consumed.loc[(df_demo['IS_FEMALE']==1)&((df_demo['AGE_PRD']==20)|(df_demo['AGE_PRD']==30)|(df_demo['AGE_PRD']==40))&(df_demo['PRVIN']=='서울특별시'), :].drop('ID', axis= 1).reset_index(drop= True)
df_specified.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2554 entries, 0 to 2553
Columns: 149 entries, H&B선물세트 to 훼이셜케어
dtypes: float64(149)
memory usage: 2.9 MB
plot_results(pt_specified[[0,1]])
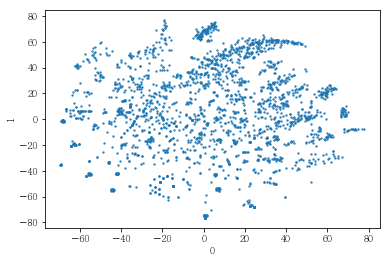
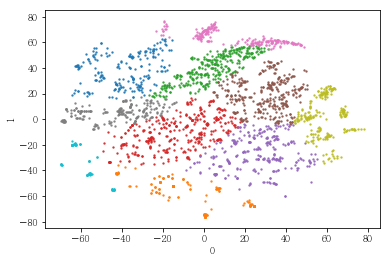
gmm = GaussianMixture(n_components=10, covariance_type='full', random_state= 42).fit(pt_specified[[0,1]])
label_dict[(2,i)]= pd.Series(gmm.predict(pt_specified[[0,1]]))
plot_results(pt_specified[[0,1]], label_dict[(2,10)])
plot_clusters(pt_specified[[0,1]], label_dict[(2,10)])