Lecture 4 Introduction to Neural Networks
Dl.cs231n.lecture| 27 Sep 2018
Tags:
DeepLearning
CS231n
- Chain rule of Derivative: Get each partial derivative with computing a chain of derivative
- add gate: distributing gradient
- max gate: gradient router
- mul gate: gradient switcher(scaler)
- 1/x gate
- exp gate or log gate
- sigmoid gate
- when calculate in vectorized form, the gradient comes as Jacobian Form, same matrix size with the shape of W.
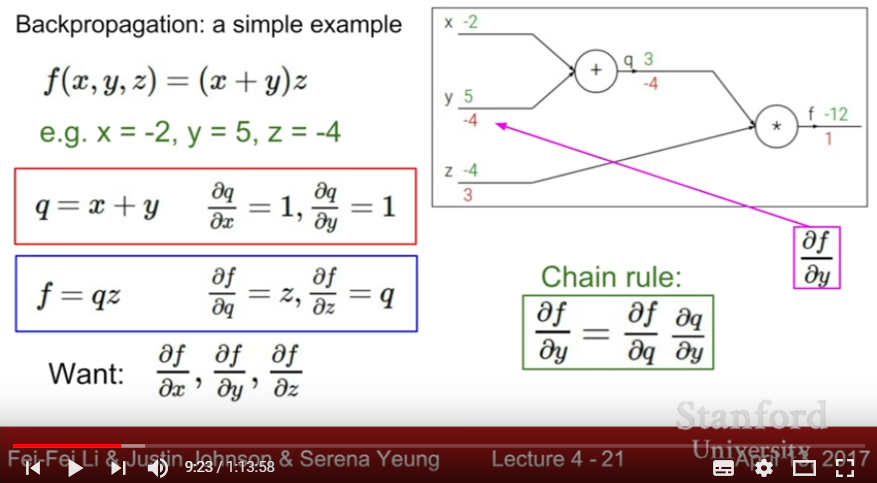

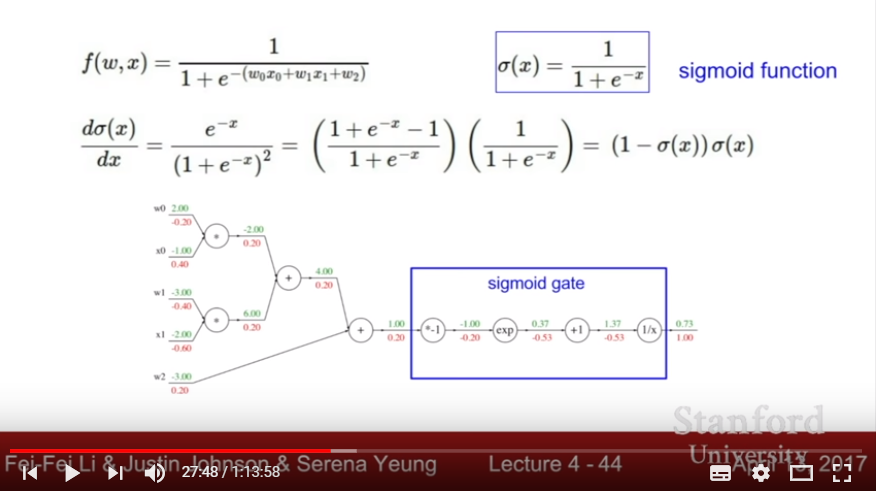
- Backpropagation: After calculating Forward prediction(propagation) and calculating loss, calculate each partial derivatives by applying chain rule of derivative, then modipy parameters with these gradient. Iterate each Forward propagation and Backward propagation to minimize loss.

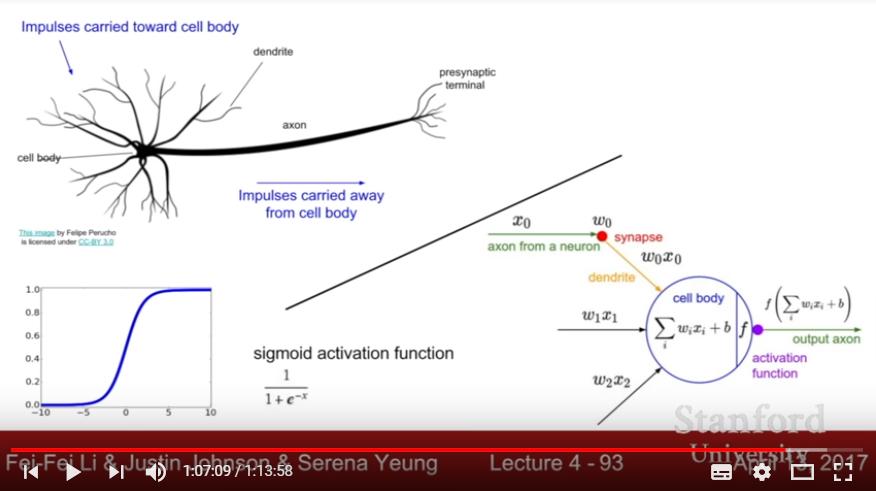
- Neural Network: Stack multiple linear matrix multiplication layer(and also an activation layer), so that model gets non-linearity or various templates.